Process spawning performance in Rust
As part of my PhD studies, I’m working on a distributed task runtime called HyperQueue. Its goal is to provide an ergonomic and efficient way to execute task graphs on High-Performance Computing (HPC) distributed clusters, and one of its duties is to be able to spawn a large amount of Linux processes efficiently. HyperQueue is of course written in Rust1, and it uses the standard library’s Command API to spawn processes2. When I was benchmarking how quickly it can spawn processes on an HPC cluster, I found a few surprising performance bottlenecks, which I will describe in this post. Even though most of these bottlenecks are only significant if you literally spawn thousands of processes per second, which is not a very common use-case, I think that it’s still interesting to understand what causes them.
Note that this is a rather complex topic, and I’m not sure if I understand all the implications of the various Linux syscalls that I talk about in this post. If you find something that I got wrong, please let me know! :)
High-Performance Command spawning
My investigation into Rust process spawning performance on Linux started a few years ago, when I was trying to measure what is the pure internal overhead of executing a task graph in HyperQueue (HQ). To do that, I needed the executed tasks to be as short as possible, therefore I let them execute an “empty program” (sleep 0). My assumption was that since running such a process should be essentially free, most of the benchmarked overhead would be coming from HyperQueue.
While running the benchmarks, I noticed that they behave quite differently on my local laptop and on the HPC cluster that I was using. After a bit of profiling and looking at flamegraphs, I realized that the difference was in process spawning. To find out what was the cause of it, I moved outside HyperQueue and designed a benchmark that purely measured the performance of spawning a process on Linux in Rust. Basically, I started to benchmark this:
Command::new("sleep").arg("0").spawn().unwrap();
Notice that here I only benchmark the spawning (i.e. starting) of a process. I’m not waiting until the process stops executing3.
If you’re interested, the benchmark harness that I have used can be found here.
On my laptop, spawning 10 000 processes takes a little bit under a second, not bad. Let’s see what happens if we do a few benchmarks to compare how long does it take to spawn N processes (displayed on the X axis) locally vs on the cluster:
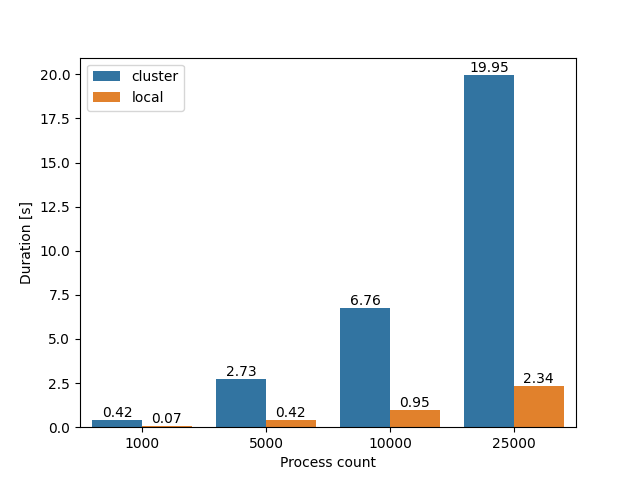
Uh-oh. For 25 thousand processes, it’s ~2.5s locally, but ~20s on the cluster, almost ten times more. That’s not good. But what could cause the difference? The cluster node has 256 GiB RAM and a 128-core AMD Zen 2 CPU, so simply put it is much more powerful than my local laptop.
Well, spawning a process shouldn’t ideally do that much work, but it will definitely perform some syscalls, right? So let’s compare what happens locally vs on the cluster with the venerable strace tool (I kept only the interesting parts and removed memory addresses and return values):
(local) $ strace ./target/release/spawn
clone3({flags=CLONE_VM|CLONE_VFORK, …}, …) = …
(cluster) $ strace ./target/release/spawn
socketpair(AF_UNIX, SOCK_SEQPACKET|SOCK_CLOEXEC, 0, [3, 4]) = …
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, … = …
close(4) = …
recvfrom(3, …) = …
Okay, it does indeed look a bit different. A different syscall (clone3 vs clone) is used, different flags are passed to it, and in addition the program opens up a Unix socket on the cluster for some reason (more on that later). Different syscalls could explain the performance difference, but why are they even different in the first place? We’ll find out soon, but first we’ll need to understand how process spawning works in Linux.
The perils of forking
Apparently, there are many ways how to create a process that executes a program on Linux, with various trade-offs. I’m not an expert in this area by any means, but I’ll try to quickly describe my understanding of how it works, because it is needed to explain the performance difference.
The traditional way of creating a new process on Linux is called forking. The fork syscall essentially clones the currently running process (hence its name), which means that it will continue running forward in two copies. fork lets you know which copy is the newly created one, so that you can do something different in it, typically execute a new program using exec, which replaces the address space of the process with fresh data loaded from some binary program.
Back in the days of yore, fork used to literally copy the whole address space of the forked process, which was quite wasteful and slow if you wanted to run exec immediately after forking, which replaces all its memory anyway. To solve this performance issue, a new syscall called vfork was introduced. It’s basically a specialized version of fork that expects you to immediately call exec after forking, otherwise it results in undefined behavior. Thanks to this assumption, it doesn’t actually copy the memory of the original process, because it expects that you won’t modify it in any way, and thus improves the performance of process spawning.
Later, fork was changed so that it no longer copied the actual contents of the process memory, and switched to a “copy-on-write” (CoW) technique. This is implemented by copying the page tables of the original process, and marking them as read-only. When a write is later attempted on such a page, it is cloned on-the-fly before being modified (hence the “copy-on-write” term), which makes process memory cloning lazy and avoids doing unnecessary work.
Since fork is now much more efficient, and there are some issues with vfork, it seems that the conventional wisdom is to just use fork, although we will shortly see that it is not so simple.
So, why have we seen clone syscalls, and not fork/vfork? That’s just an implementation detail of the kernel. These days, fork is implemented in terms of a much more general syscall called clone, which can create both threads and processes4, and can also use “vfork mode”, where it doesn’t copy memory of the original process before executing the new program.
Armed with this knowledge, let’s compare the syscalls again:
(local)
clone3({flags=CLONE_VM|CLONE_VFORK, …}, …) = …
(cluster)
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, … = …
The clone3 call is essentially a vfork, since it uses the CLONE_VM and CLONE_VFORK flags, while the clone call used on the cluster is essentially a fork.
So, what causes the difference? We’ll have to take a look inside the Rust standard library to find out. The Unix-based Command::spawn implementation is relatively complicated (partly because it supports multiple operating systems and platforms at once). It does a bunch of stuff that I don’t completely understand, and that would probably warrant a blog post of its own, but there is one peculiar thing that immediately caught my attention - it exercises a different code-path based on the version5 of glibc (the C standard library implementation) of your environment:
- It you have at least
glibc 2.24, it will use a “fast path”, which involves calling theposix_spawnpglibcfunction, which then in turns generates the efficientclone3(CLONE_VM|CLONE_VFORK)syscall (effectivelyvfork). - If you have an older
glibcversion (or if you use some complicated spawn parameters), it instead falls back to just callingforkdirectly, followed byexecvp. In addition, it also creates a UDS (Unix Domain Socket) pair to exchange some information between the original and the forked process6, which explains thesocketpairandrecvfromsyscalls that we saw earlier.
When I saw that, I was pretty sure that this is indeed the source of the problem, since I already had my share of troubles with old glibc versions on HPC clusters before. Sure enough, my local system has glibc 2.35, while the cluster still uses glibc 2.17 (which is actually the oldest version supported by Rust today).
Good, now that we at least know why different syscalls are being generated, let’s try to find out why is their performance different. After all, shouldn’t fork be essentially as fast as vfork these days?
fork vs vfork (are you gonna need that memory?)
To better understand what is happening, and to make sure that the effect is not Rust-specific, I wrote a very simple C++ program that tries to replicate the process spawning syscalls executed by the Rust standard library by executing the posix_spawn function. To select between fork vs vfork “semantics”, I use the POSIX_SPAWN_USEVFORK flag. Let’s see what happens locally vs on the cluster again:
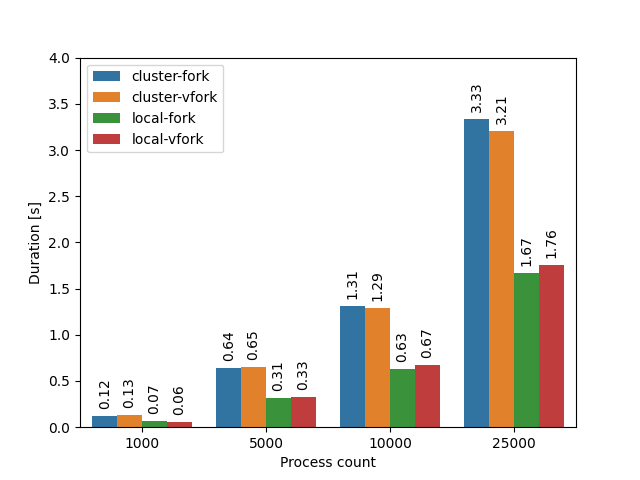
Okay, it’s indeed slower on the cluster, which can be probably attributed to an older kernel (3.10 vs 5.15) and/or older glibc (2.17 vs 2.35), but it’s nowhere as slow as before. So what gives? Is it Rust’s fault? Well, let’s see what happens if we benchmark the spawning of 10000 processes, but this time we will progressively increase the RSS (the amount of allocated memory) of the original process by allocating some bogus memory up-front:
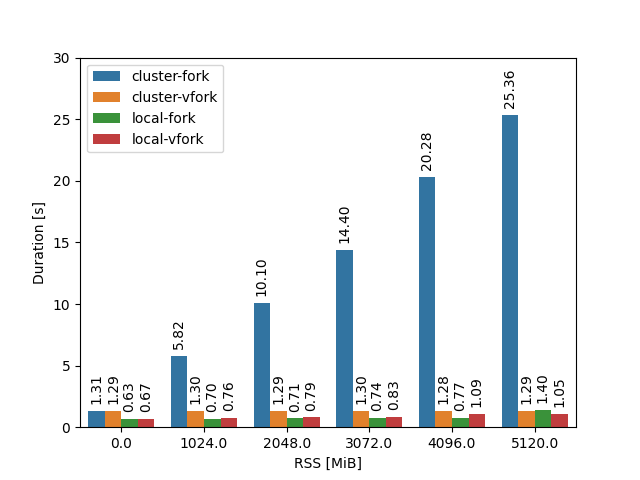
…is it just me or does one of the bars stand out? ![]()
First, let’s try to understand why is fork still so fast on my laptop, even though it became much slower on the cluster. We can find the answer in the documentation of the POSIX_SPAWN_USEVFORK flag:
POSIX_SPAWN_USEVFORK
Since glibc 2.24, this flag has no effect. On older
implementations, setting this flag forces the fork() step
to use vfork(2) instead of fork(2). The _GNU_SOURCE
feature test macro must be defined to obtain the
definition of this constant.
In other words, if you have at least glibc 2.24, this flag is basically a no-op, and all processes created using posix_spawn (including those created by Rust’s Command) will use the fast vfork method by default, making process spawning quite fast. This basically shows that there’s no point in even trying to debug/profile this issue on my local laptop, since with a recent glibc, the slow spawning will be basically unreproducible.
Note that Rust doesn’t actually set the
POSIX_SPAWN_USEVFORKflag manually. It just benefits from the faster spawning by default, as long as you haveglibc 2.24+.
Now let’s get to the elephant in the room. Why does it take 5 seconds to spawn 10 000 processes if I have first allocated 1 GiB of memory, but a whopping 25 seconds when I have already allocated 5 GiB? The almost linear scaling pattern should give it away - it’s the “copy-on-write” mechanism of fork. While it is true that almost no memory is copied outright, the kernel still has to copy the page tables of the previously allocated memory, and mark them as read-only/copy-on-write. This is normally relatively fast, but if you do it ten thousand times per second, and you have a few GiB of memory allocated in your process, it quickly adds up. Of course, I’m far from being the first one to notice this phenomenon, but it still surprised me just how big of a performance hit it can be.
This also explains why this might not show up in trivial programs, but can be an issue in real-world applications (like HyperQueue), because these will typically have a non-trivial amount of memory allocated at the moment when the processes are being spawned.
Just to double-check that I’m on the right track, I also checked a third programming language, and tried to benchmark subprocess.Popen(["sleep", "0"]) in Python 3:
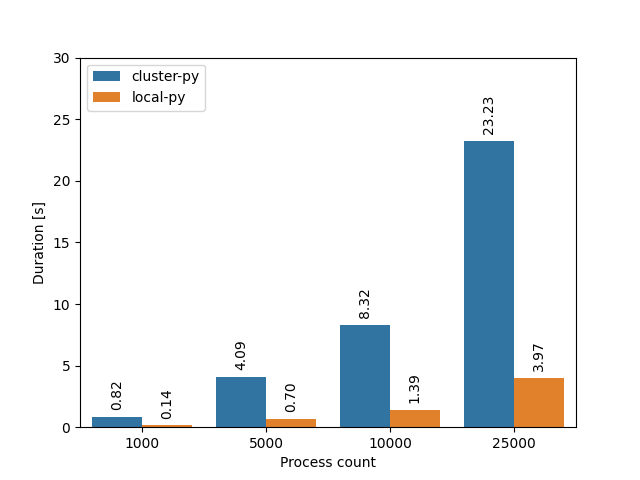
Sure enough, it’s again much slower on the cluster. And if we peek inside with strace again, we’ll find that on the cluster, Python uses clone without the CLONE_VFORK flag, so esssentially the same thing as Rust, while locally it uses the vfork syscall directly.
Ok, so at this point I knew that some of the slowdown is obviously caused by the usage of fork (and some of it is probably also introduced by the Unix sockets, but I didn’t want to deal with that). I saw that even on the cluster, I can achieve much better performance, but I would need to avoid the fork slow path in the Rust standard library and also add the POSIX_SPAWN_USEVFORK flag to its posix_spawnp call.
By the way, there is also another common solution to this problem, to use a “zygote” process with small RSS, which is
forked repeatedly to avoid the page table copying overhead. But it doesn’t seem like it would help here,
because in Rust, even the small benchmark program with small RSS was quite slow to fork using the
slow path approach. Perhaps the overhead lies in the UDS sockets, or something else.
Should we use vfork?
After I learned about the source of the bottleneck, I created an issue about it in the Rust issue tracker7. This led me to investigate how other languages deal with this issue. We already saw that Python uses the slow method with older glibc. I found out that Go (which AFAIK actually doesn’t use glibc on Linux and basically implements syscalls from scratch) switched to the vfork method in 1.9, which produced some nice wins in production.
However, I was also directed to some sources from people much more knowledgeable about Linux than me, that basically explained that there is a reason why vfork wasn’t being used for older glibc versions, and that reason is because these old glibc versions implemented it in a buggy way.
So I decided that it’s probably not a worthwhile effort to push this further and risk the option of introducing arcane glibc bugs, and I closed the issue. As we’ll see later, this wasn’t the only bottleneck in process spawning on the cluster, though.
Aside: modifying the standard library
When I first learned about the issue and saw that the POSIX_SPAWN_USEVFORK flag fixes the performance problem on the cluster, I was a bit sad at first that what would have been essentially a one-line change in C or C++ (since they do not really have any high-level standard library API for spawning processes) would require me to either propose a change deep within, or fork, the Rust standard library (neither of which is trivial).
However, I realized that this line of thinking is misleading. Yes, it would be a one-line change in C or C++, but only because in these languages, I would have to first write the whole process spawning infrastructure myself! Or I would have to use a third-party library, but then I would encounter a similar issue - I would either have to fork it, copy-paste it in my code or get a (potentially controversial) change merged to it. I’m actually really glad that it’s so easy to use third-party libraries in Rust and that the standard library allows me to use fundamental functionality (like process spawning) out of the box. But there are trade-offs everywhere - one implementation can never fit all use-cases perfectly, and if you’re interacting with an HPC cluster with a 10-year-old kernel, the probability of not fitting within the intended use-case increases rapidly ![]() .
.
So why couldn’t I just copy-paste the code from the standard library into my own code, modify it and then use the modified version? Well, this would be an option, of course, but the issue is that it would be a lot of work. I need process spawning to be asynchronous, and thus in addition to modifying the single line in the standard library, I would also need to copy-paste the whole of std::process::Command, and also tokio::process::Command, and who knows what else.
If it was possible to build a custom version of the standard library in an easier way, I could just keep this one-line change on top of the mainline version, and rebuild it as needed, without having to modify all the other Rust code that is built on top of it (like tokio::process::Command). And since Rust links to its standard library statically by default, it shouldn’t even cause problems with distributing the final built binary. Hopefully, build-std will be able to help with this use-case one day.
As I already stated in the introduction, it’s important to note that the bottleneck that I’m describing here has essentially only been showing in microbenchmarks, and it usually isn’t such a big problem in practice. If it was a larger issue for us, I would seriously consider the option of copy-pasting the code, or writing our own process spawning code from scratch (but that would increase our maintenance burden, so I’d like to avoid that if possible).
It’s all in the environment
I thought that the fork vs vfork fiasco was the only issue that I was encountering, but after performing more benchmarks, I found out another interesting bottleneck. I was still seeing some unexpected slowdown on the cluster that couldn’t have been explained by the usage of fork alone. After another round of investigation, I noticed that on the cluster, there is a relatively large amount (~180) of environment variables that amounted to almost 30 KiB of data. Could this also pose a performance problem? Let’s see what happens if we spawn 10 000 processes again, but this time we progressively increase the amount of environment variables set in the process:
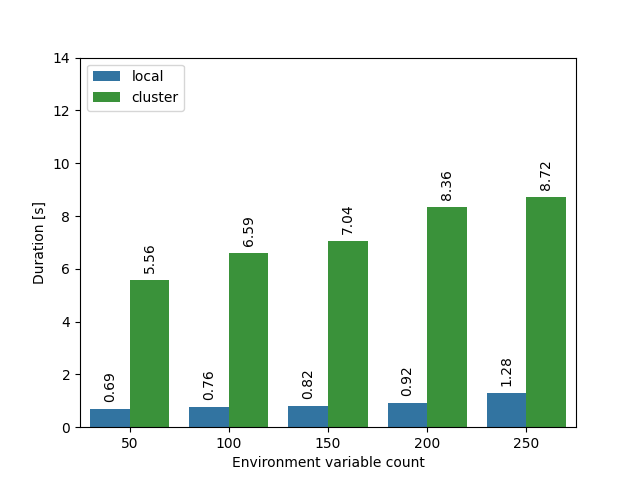
Clearly, the amount of environment variables has an effect! And as usually, it’s much higher on the cluster than on my local laptop. Increasing the amount of environment variables from 50 to 250 makes the spawning 50% slower!
We will need to take another look inside the Rust standard library to see what happens here. The chart above actually shows a “fast path”. Since I only execute Command::new(...).spawn(), without setting any custom environment variables and without clearing the environment, stdlib recognizes this and doesn’t actually process the environment variables in any way. It simply passes the environ pointer from glibc directly to posix_spawn or execvp (as we already know, depending on your glibc version).
I’m not sure why does the spawning get so much slower with more environment variables, but I assume that it’s simply by the kernel having to copy all these environment variables to the address space of the new process.
What if we don’t go through the fast path? If we set even just a single environment variable for the spawned command, it will no longer be possible to just copy the environment of the original process, and therefore it will need to be built from scratch for each single spawned command (the -set variants set an environment variable, the -noset variants do not):
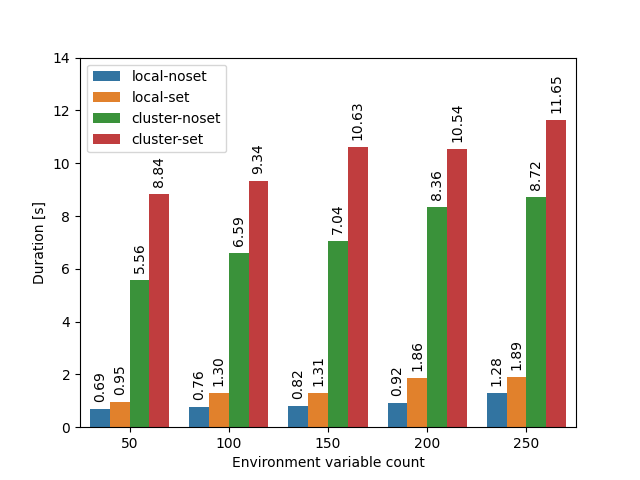
What does the building of a fresh environment entail? The current environment is combined with the environment variables set on the Command being spawned, and the result is stored in a BTreeMap. It is then converted to an array of C strings that is then eventually passed as an array of char* pointers to posix_spawnp or execvp. During this process, each environment key and value is copied several times, and the environment list is also sorted (by being inserted into the BTreeMap). This contributes to the spawning overhead if you create a lot of processes and your process has hundreds of environment variables.
I tried to take a shot at optimizing the fresh environment preparation, to reduce some of the allocations and also remove the sorting, which (AFAIK) isn’t needed on Linux. I performed some benchmarks using the new version, but they were quite inconclusive, so I won’t even show them here, because I’m not really confident that my change produced a real speed-up. And even if it did, I’m not sure if it’s worth the additional complexity, especially when the bottleneck only shows up when you have a large amount of environment variables. I wanted to also try benchmarking it on the cluster, but I would have to build a toolchain of the compiler that supports glibc 2.17 for that, and I wasn’t motivated enough to do that yet.
Can we parallelize this?
One of the things that I tried to make the process spawning faster (both for fork and vfork) was to parallelize it. While investigating this possibility, I realized a few things:
-
tokio::process::Command::spawnis actually a blocking function. Since HyperQueue uses a single-threadedtokioruntime, it is not possible to truly concurrently spawn multiple processes. I will either need to use the multithreadedtokioruntime, or usespawn_blocking. - The documentation of
CLONE_VFORK(which is thecloneflag that enables “vfork mode”) claims this:CLONE_VFORK (since Linux 2.2) If CLONE_VFORK is set, the execution of the calling process is suspended until the child releases its virtual memory resources via a call to execve(2) or _exit(2) (as with vfork(2)).In other words, it claims that the whole process (not just the calling thread) is suspended when a new process is being spawned. If this was indeed true, parallelization probably wouldn’t help that much. However, I did some experiments, and it seems that it indeed just stops the thread that spawns the new process, so this might be a bit misleading. The documentation of
vforksupports this:When vfork() is called in a multithreaded process, only the calling thread is suspended until the child terminates or executes a new program.But I’m not sure if the semantics of
vforkvsclone(CLONE_VFORK)are the same…
I didn’t have a lot of energy left to examine this in detail, so I just executed a few benchmarks that spawn 20 000 processes in several asynchronous “modes”:
-
single: Use a single-threadedtokioruntime. -
singleblocking: Use a single-threadedtokioruntime, but wrap theCommand::spawncall inspawn_blocking. -
multi-n: Use a multithreadedtokioruntime withnworker threads.
Here are the results, again on my local laptop vs on the cluster:
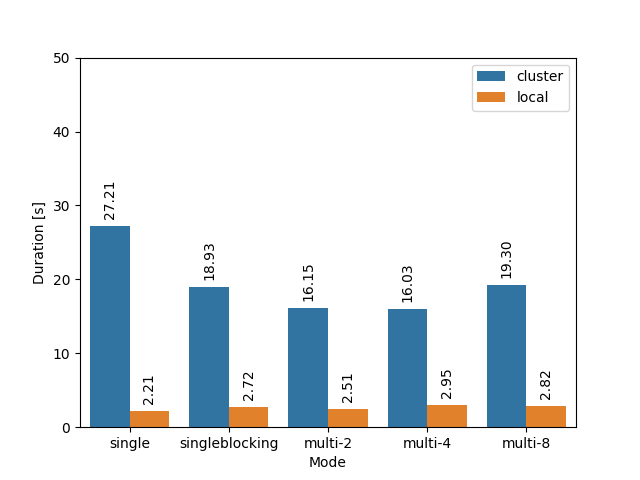
Locally, parallelizing doesn’t really seem to help, but on the cluster it provides some speedup. An even larger speedup is achieved if there is more (blocking) work to be done per spawn, e.g. when we set an environment variable on the spawned command, and thus we have to go through the dance of building the fresh environment:
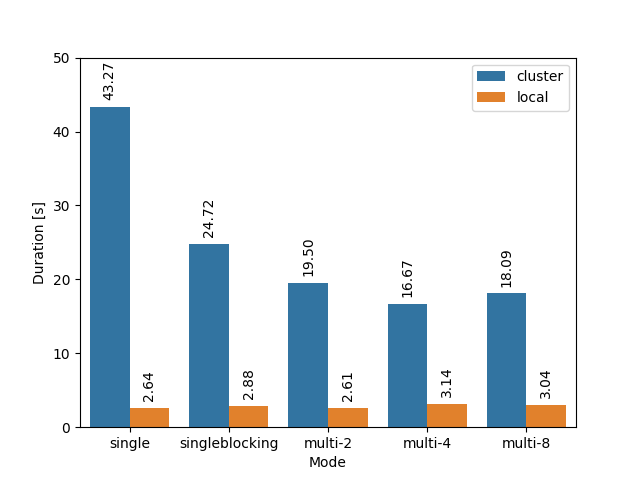
In HyperQueue, we can’t (and don’t want to) easily switch to a multithreaded runtime, but the spawn_blocking approach looks relatively promising.
Bonus: sleep vs /usr/bin/sleep
Since I’m focusing on micro-benchmarks in this blog post, let’s see one more. Do you think that there is any performance difference between spawning a process that executes sleep vs spawning a process that executes /usr/bin/sleep? No tricks are being played here, these two paths lead to the same binary. It turns out that there is:
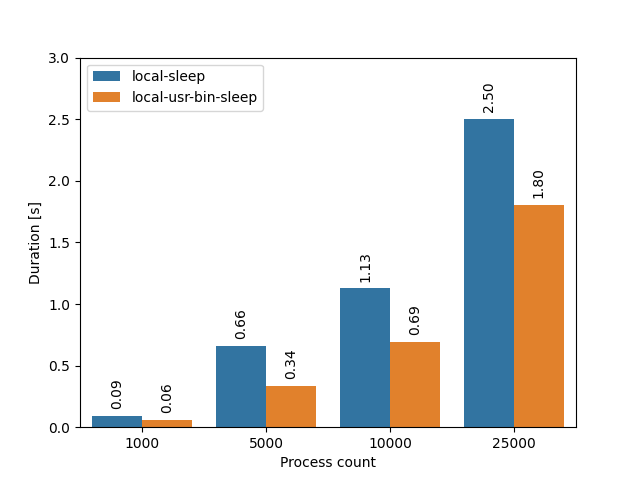
The difference is not large, but it is there. Why? When you specify an absolute path, the binary can be executed directly. However, if you just specify a binary name, then the operating system first has to find the actual binary that you want to execute, by iterating through directories in the PATH environment variable. For reference, my PATH environment variable had 14 entries and 248 bytes in total, so it’s not exactly gargantuan. But again, if you spawn thousands of processes, it all adds up :)
Conclusion
I hope that you have learned something new about process spawning on Linux using Rust. Even though I think that the presented bottlenecks won’t cause any issues for the vast majority of Rust programs, if you’ll ever need to spawn a gigantic amount of processes in a short time, perhaps this blog post could serve as a reference on what to watch out for.
I’m pretty sure that it would be possible to dive much deeper into this complex topic, but I already spent enough time on it, at least for now. If you have any comments or questions, please let me know on Reddit.
-
Before we knew Rust, we were developing distributed systems in our lab in C++. Suffice to say… it was not a good idea. ↩
-
Well, it actually uses
tokio::process::Command, but that’s just an async wrapper overstd::process::Commandanyway. ↩ -
Although my benchmark harness does wait for all the spawned processes to end after each benchmark iteration (this waiting is not part of the measured duration), otherwise Linux starts to complain pretty quickly that you’re making too many processes without joining them. ↩
-
To the Linux kernel, these are essentially the same thing anyway, just with different memory mappings and other configuration. ↩
-
Fun fact: the standard library parses the glibc version every time you try to spawn a process. Luckily, it’s probably just a few instructions. ↩
-
I don’t really know why that happens, and I was lazy to search
git blameto find the original motivation. Seems to be related to signal safety. Anyway, this blog post is already long enough without delving deeper into this. ↩ -
Funnily enough, I basically rediscovered all of what I describe in this blog post by performing many experiments 2.5 years later, rather than just re-reading my old issue…
 ↩
↩